
In my first blog post, I talked about some of the shady stuff going behind the academic system and how that can upheave trust in the scientific community.
This post, I will be addressing a more subtle form of academic practice, something that has academics falling across both sides of the fence.
Hypothesizing after results are known
Generally, the scientific method relies on 1) conducting a thorough literature review; 2) proposing a research question; and finally 3) proposing a hypothesis to answer said question. A hypothesis forms the backbone of most research projects – it is after all the one criteria/prediction that will be empirically tested and the key point of interest for most readers to home into. So entrenched is this methodology of conducting research that publishing a study without a hypothesis is (to my knowledge) pretty much impossible nowadays, at least in the sciences. Over the course of the hundreds of papers I read throughout my Ph.D., I do not recall a single experimental study done without a hypothesis*.
*The exception is in Nature, Science and PNAS, which follows a unique format that makes hypotheses in these papers not as explicit
The method exists for a good reason (MOST of the time, more on this in a different post) – it is what makes science empirically testable and falsifiable. Ideally, you would go about creating a hypothesis through sound reasoning and well-informed by the literature, then conduct an experiment that shows the results that supports your hypothesis.
Ideally.
Anyone who works in biology/ecology has seen this next part before. Practically, your results were not statistically significant, or has too small an effect size, or directly contradicted your initial prediction (pick any 2). What now?
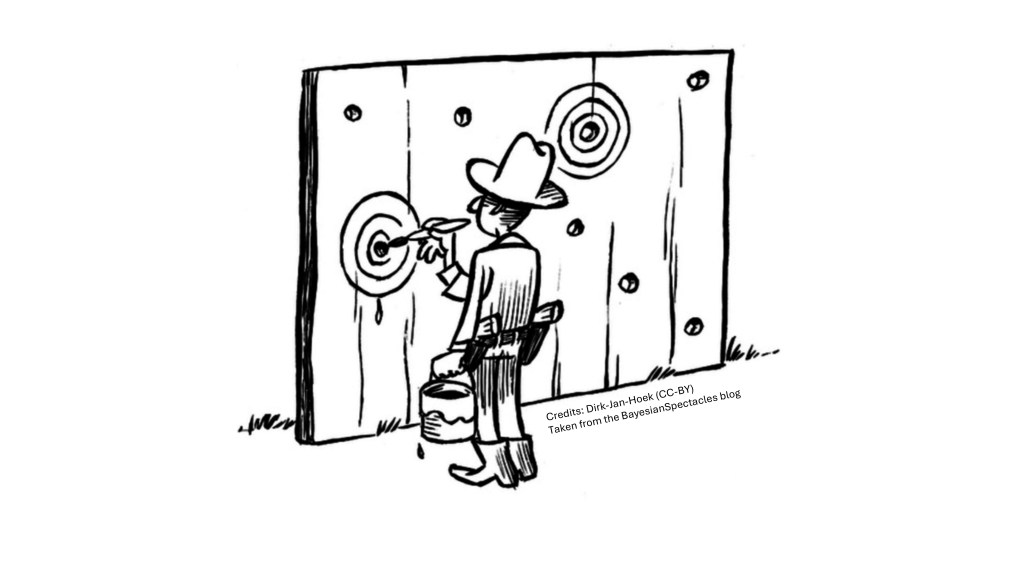
In an ideal world, assuming your hypothesis was sound, you write up your research as per normal, show your results honestly and conclude that perhaps your hypothesis lacked empirical support, which warrants further study/a new rationale/larger sample size (pick any 3). In practice, two ugly truths hit you. The first was covered in my first post – unscrupulous researchers tweaking their data for the sake of a compelling story. The second is a bit more… sketchy – how about changing the hypothesis so that it seems like your results supported it? The latter practice is known as Hypothesising After Results are Known (HARKing for short; term coined by Dr. Norbert L. Kerr in his 1998 paper).
The grey zone of HARKing
HARKing presents itself in many forms. Discarding any a priori hypotheses that was unsupported by the data is technically HARKing. Switching your predicted trend (e.g. predicting a negative instead of a positive relationship when a negative association is found) when the literature is undecided on a phenomenon counts as HARKing too. Creating a new hypothesis after seeing results is technically nothing wrong but presenting it sneakily as an a priori prediction counts as HARKing.
Not everyone agrees that each of these scenarios is wrong. Take for example the first scenario. Being forced to discard unsupported hypotheses is clearly not ideal, but given the page/word constraints set by journals plus the general lack of interest in null results, it is fairly easy to see why when a manuscript gets trimmed, the parts which do not align with the authors’ story gets the axe first.
In the second scenario, if the literature has provided evidence (and a strong rationale) that the relationship between X and Y could be either positive/negative, how you craft your a priori essentially becomes a coin flip (barring any other useful information). Losing that coin flip could easily make the difference between crafting an interesting story that will entice an editor to take a further look at, or writing about a null result that gets your manuscript an express ticket to the rejection pile. In such an event, a budding researcher might find it obvious to quietly reverse his original prediction – after all, such an expectation is rooted in a sound rationale.
What if something interesting yet unexpected comes out? The temptation to be the first to write something about it is immensely compelling to any scientist worth his/her salt. Yet, because there was no expectation for said result in the first place, crafting a story that deviates from the classic journal trope of Introduction >> Hypotheses >> Results >> Discussion is harder (and riskier from a publication standpoint). Much easier to sneak in a new hypothesis that showed you predicted this all along (and making you look like a genius, assuming you found a good reason why such a trend is expected after all)! I am willing to bet this last scenario is EXTREMELY COMMON in labs with tight wallets, and/or run by advisers who take a shotgun approach to science (collecting as many variables and data as possible under a tight budget and pray something interesting pops out). For researchers striving for tenurehood, publishing a milestone paper may make the difference between a secure job for the next two decades, or getting the boot tomorrow. In that case, they’ll do anything to make their work look as polished as possible.
I don’t think any of these issues are unique to my field. To me, HARKing appears to be most prevalent in fields where the mechanisms and principles are murky and hard to control/define. Think psychology, sociology, biology, ecology and medicine – how hard is it to create a perfectly-controlled experiment on living bodies, or ecosystems, or human participants? These fields can often produce multiple theories and predictions to explain the same trend. Properly representing the field’s consensus would necessitate highlighting all these theories in your introduction (even if they may be competing). After that, which of their predictions do you go with?
As an example, try to answer the following (there are sources backing up each of the following statements):
Roots acquire soil phosphorus (P) for plant growth. In low-P soils, would you hypothesise (a priori):
- roots to increase in length and thinness? (to increase surface area for absorbing soil nutrients);
- roots to decrease in length and thinness? (to increase their durability to reduce the loss of existing plant nutrient stocks through root turnover);
- no relationship between root length/thinness and soil nutrients? (because of alternative strategies to acquire nutrients, such as mycorrhiza);
- no relationship between root length/thinness and soil nutrients? (because A and B can be both correct depending on species, cancelling each effect out across a wide species pool);
- <insert some other reason>
Now, imagine if you chose wrongly, found a different result, took delicate care to explain why the results weren’t as expected, then get rejected for “uninteresting results”.
Isn’t it fun to do research sometimes?
HARKing compromises the scientific enterprise
HARKing is a major problem because at its heart, it is a practice of deception. This isn’t a moral issue – it has literal statistical implications. Because of how prevalent the use of p-values is in the sciences, there is always a danger of type I errors (false positive results); typically set at 5% in most fields. When we run multiple tests, the possibility of encountering at least one type I error skyrockets. That itself isn’t a problem as long you know that these additional tests were done in earnest. The problem comes in when authors hide those null results, giving the false impression that the type I error was only 5%, when it could be more than 50% had you conducted at least 14 tests. Imagine trying to replicate a study with a 50% type I error rate…
Secondly, by HARKing, researchers give a false portrayal of the scientific process and the number of duds they encounter in their research. We present a façade in science that our work always leads to a cool story, where in reality this is nowhere near the case. Null findings are just as essential a part of science as the significant stuff, and so much time and resources could be saved globally if we remain transparent on what was tried (and didn’t work). As scientists, we are entrusted by the public to be as objective as possible with our work. Somewhere along the way, we sacrificed this aspect of the scientific enterprise for the sake of an eye-catching narrative.
Is there a better way forward?
I used to think it was a clear-cut issue that HARKing is wrong (that was what I was taught in grad school). Now, with the reality of publishing setting in, I do find myself in occasional conflict with my advisor on editing the hypotheses of our manuscripts. I try to be as honest as possible in my work even in writing, and so I feel one should not even look at the analysis of the data before setting the hypothesis in stone. My advisor feels there is nothing wrong with modifying one’s hypothesis as long as it can be justified by past work and sound theory. Maybe I’m too naïve? Let me know in the comments.
Maybe in the future, there will be a new way to publish science that circumnavigates all these grey zones. I see some promising developments in journals willing to publish null results, doing away with p-values, and prematurely registering studies to prevent manipulation of results and hypotheses. Personally, these are great moves that show researchers are growing wise to the problems in how we do science. But nothing will change unless our cut-throat culture of “publish or perish”, publication bias and editors flat-out refusing to accept replication studies is eradicated, freeing scientists of the perverse incentives to publish great-sounding, yet intellectually dishonest studies.






Leave a comment